, 17 7 : 3 3 . 6 6 " 4 2 et 4 2 le 6 2 tout 1 5 un 5 2
<?xml version="1.0" encoding="utf-8"?> <TEI version="3.3.0" xmlns="http://www.tei-c.org/ns/1.0"> <teiHeader> <fileDesc> <titleStmt><title> Deux fables de La Fontaine (Dénombrement sur contextes) </title></titleStmt> <publicationStmt> <p>Document produit par le logiciel SATO</p></publicationStmt> </fileDesc> </teiHeader> <text> <body> <div type="Statistiques"> <ab type="Sommaire"> <measure type="Corpus_OccNbr" quantity="318"/> <measure type="Contexte_OccNbr" quantity="318"/> <measure type="Contexte_Nbr" quantity="2"/> <measure type="Objet_Nbr" quantity="9"/> </ab> </div> <div type="Objet"> <fs xml:id="obj1" n="1"> <f name="Effectif"><numeric value="6"/></f> <f name="Contexte_Nbr"><numeric value="2"/></f> <f name="Description"><string>"</string></f> <f name="Id"><string>Nolex=2</string></f> </fs> <fs xml:id="obj2" n="2"> <f name="Effectif"><numeric value="24"/></f> <f name="Contexte_Nbr"><numeric value="2"/></f> <f name="Description"><string>,</string></f> <f name="Id"><string>Nolex=3</string></f> </fs> <fs xml:id="obj3" n="3"> <f name="Effectif"><numeric value="12"/></f> <f name="Contexte_Nbr"><numeric value="2"/></f> <f name="Description"><string>.</string></f> <f name="Id"><string>Nolex=5</string></f> </fs> <fs xml:id="obj4" n="4"> <f name="Effectif"><numeric value="6"/></f> <f name="Contexte_Nbr"><numeric value="2"/></f> <f name="Description"><string>:</string></f> <f name="Id"><string>Nolex=6</string></f> </fs> <fs xml:id="obj5" n="5"> <f name="Effectif"><numeric value="6"/></f> <f name="Contexte_Nbr"><numeric value="2"/></f> <f name="Description"><string>et</string></f> <f name="Id"><string>Nolex=58</string></f> </fs> <fs xml:id="obj6" n="6"> <f name="Effectif"><numeric value="8"/></f> <f name="Contexte_Nbr"><numeric value="2"/></f> <f name="Description"><string>le</string></f> <f name="Id"><string>Nolex=80</string></f> </fs> <fs xml:id="obj7" n="7"> <f name="Effectif"><numeric value="6"/></f> <f name="Contexte_Nbr"><numeric value="2"/></f> <f name="Description"><string>tout</string></f> <f name="Id"><string>Nolex=148</string></f> </fs> <fs xml:id="obj8" n="8"> <f name="Effectif"><numeric value="7"/></f> <f name="Contexte_Nbr"><numeric value="2"/></f> <f name="Description"><string>un</string></f> <f name="Id"><string>Nolex=150</string></f> </fs> <fs xml:id="obj9" n="9"> <f name="Effectif"><numeric value="75"/></f> <f name="Contexte_Nbr"><numeric value="2"/></f> <f name="Description"><string>plus5</string></f> </fs> </div> <div type="Contexte" xml:base="fable.xml"> <span from="#w1" to="#w189" xml:id="w1-w189" n="170"> <cb n="1"/>4<cb n="2"/>17<cb n="3"/>6<cb n="4"/>3<cb n="5"/>4<cb n="6"/>6<cb n="7"/>1<cb n="8"/>5<cb n="9"/>46 </span> <span from="#w190" to="#w358" xml:id="w190-w358" n="148"> <cb n="1"/>2<cb n="2"/>7<cb n="3"/>6<cb n="4"/>3<cb n="5"/>2<cb n="6"/>2<cb n="7"/>5<cb n="8"/>2<cb n="9"/>29 </span> </div> </body> </text> </TEI>
Comme on le voit, ce fichier est auto-documenté et contient beaucoup plus d'informations qu'un simple tableau. En voici les composants.
- Le bloc <teiHeader>...</teiHeader> documente le fichier.
- Le bloc <div type="Statistiques">...</div> contient des informations numériques sur le nombre d'occurrences dans le corpus et dans les contextes ainsi que le nombre de contextes et d'objets dénombrés.
- Le bloc <div type="Objet">...</div> décrits les objets eux-mêmes.
- Le bloc <div type="Contexte">...</div> décrits les contextes avec la suite des colonnes du tableau qui contiennent le décompte de l'objet correspondant s'il n'est pas zéro. Par exemple <cb n="1"/>4 indique que l'objet 1 a 4 occurrences dans ce segment de texte. Même si ce fichier semble lourd, il en général plus petit que la matrice du format tabulaire qui contient souvent une majorité de colonnes à zéro. Aussi, ce fichier XML contient tout ce qu'il faut pour faire une variété de calculs indépendamment du logiciel SATO. À terme, on pourrait supprimer le format tabulaire puisque l'on peut générer la matrice de données à partir du fichier XML.
Appliquer
APPLIQUER lance l'exécution de l'analyseur.
Six options s'appliquent à l'application : DIFFÉRENCES, FRÉQUENCES, LEXÈMES, MOTS, NOUVEAUX et VALEURS.
Les options DIFFÉRENCES et NOUVEAUX permettent de repérer l'arrivée de nouveaux termes dans le déroulement d'un texte. On peut donc avoir une idée des points de discontinuité correspondant à des changements de thème par exemple. DIFFÉRENCES donne le nombre de lexèmes du segment courant qui n'étaient pas présents dans le segment précédent. NOUVEAUX donne le nombre de lexèmes du segment courant qui n'apparaissaient dans aucun segment précédent. L'option LEXÈMES permet quant à elle d'évaluer la présence d'un vocabulaire donné dans les différents segments. Finalement, l'option MOTS évalue l'importance de l'utilisation (nombre d'occurrences) de ce vocabulaire.
L'option FRÉQUENCES est semblable à l'option MOTS. La différence tient à ceci : avec l'option MOTS, le décompte se fait sur l'ensemble des lexèmes désignés par un filtre; avec l'option FRÉQUENCES, le décompte s'effectue sur chacun des lexèmes désignés par un filtre.
Appliquer Différences
DIFFÉRENCES : pour compter le nombre de lexèmes d'un contexte qui diffèrent de ceux du contexte précédent.
Les occurrences qui seront soumises au décompte sont désignées par le patron de fouille filtre; la valeur implicite du filtre est «$» (tous les mots).
Le paramètre nom sert à identifier la liste des résultats du décompte. Il suit la syntaxe du symbole, c'est-à-dire qu'il doit s'exprimer comme une chaîne alphanumérique ou comme une chaine de caractères entre guillemets anglais ("). On peut terminer la commande par l'option XML (nouveau fichier XML) ou +XML (ajout à fichier XML) pour écrire les résultats dans un fichier au format XML-TEI.
Appliquer Fréquences
FRÉQUENCES : pour compter les fréquences (nombre d'occurrences par contexte) pour chacun des lexèmes.
Les occurrences qui seront soumises au décompte sont désignées par le patron de fouille filtre; la valeur implicite du filtre est «$» (tous les mots).
L'option FRÉQUENCES ne requiert pas d'identificateur de liste. Les caractères de chacun des lexèmes désignés par le filtre serviront alors d'identificateurs. On peut terminer la commande par l'option XML (nouveau fichier XML) ou +XML (ajout à fichier XML) pour écrire les résultats dans un fichier au format XML-TEI.
Appliquer Lexèmes
LEXÈMES : pour compter le nombre de lexèmes par contexte.
Les occurrences qui seront soumises au décompte sont désignées par le patron de fouille filtre; la valeur implicite du filtre est «$» (tous les mots).
Le paramètre nom sert à identifier la liste des résultats du décompte. Il suit la syntaxe du symbole, c'est-à-dire qu'il doit s'exprimer comme une chaîne alphanumérique ou comme une chaine de caractères entre guillemets anglais ("). On peut terminer la commande par l'option XML (nouveau fichier XML) ou +XML (ajout à fichier XML) pour écrire les résultats dans un fichier au format XML-TEI.
Voir : Exemple 2 - Analyseur comptage appliquer lexèmes.Appliquer Mots
MOTS : pour compter le nombre d'occurrences par contexte pour l'ensemble des lexèmes.
Les occurrences qui seront soumises au décompte sont désignées par le patron de fouille filtre; la valeur implicite du filtre est «$» (tous les mots).
Le paramètre nom sert à identifier la liste des résultats du décompte. Il suit la syntaxe du symbole, c'est-à-dire qu'il doit s'exprimer comme une chaîne alphanumérique ou comme une chaine de caractères entre guillemets anglais ("). On peut terminer la commande par l'option XML (nouveau fichier XML) ou +XML (ajout à fichier XML) pour écrire les résultats dans un fichier au format XML-TEI.
Voir : Exemple 2 - Analyseur comptage appliquer mots.Appliquer Nouveaux
NOUVEAUX : pour compter le nombre de lexèmes par contexte qui diffèrent de l'ensemble des contextes précédents.
Les occurrences qui seront soumises au décompte sont désignées par le patron de fouille filtre; la valeur implicite du filtre est «$» (tous les mots).
Le paramètre nom sert à identifier la liste des résultats du décompte. Il suit la syntaxe du symbole, c'est-à-dire qu'il doit s'exprimer comme une chaîne alphanumérique ou comme une chaine de caractères entre guillemets anglais ("). On peut terminer la commande par l'option XML (nouveau fichier XML) ou +XML (ajout à fichier XML) pour écrire les résultats dans un fichier au format XML-TEI.
Appliquer Valeurs
VALEURS : pour compter le nombre d'occurrences par contexte pour chacune des valeurs d'une propriété lexicale.
Les occurrences qui seront soumises au décompte sont désignées par le patron de fouille filtre; la valeur implicite du filtre est «$» (tous les mots).
L'option VALEURS ne requiert pas d'identificateur de liste. Dans ce cas, chacune des valeurs d'une propriété désignée servira d'identificateur.
Le paramètre propriété désigne le nom d'une propriété lexicale dont les valeurs serviront d'entrées aux décomptes. On peut terminer la commande par l'option XML (nouveau fichier XML) ou +XML (ajout à fichier XML) pour écrire les résultats dans un fichier au format XML-TEI.
Supprimer
Cette action supprime le contenu du fichier d'extraction, aussi appelé fichier de statistiques, sur lequel sont inscrits les résultats du comptage.
Caractériser
CARACTÉRISER permet de modifier certains traits de fonctionnement de l'analyseur. Ces paramètres sont : EXTRACTION, SOMMAIRE et SAUVEGARDE.
Caractériser Extraction
La production du décompte pour chaque contexte et son inscription dans le fichier d'extraction n'est pas toujours nécessaire. Quelques fois, le sommaire suffit. Dans ce cas, on peut caractériser le trait EXTRACTION à la valeur NON. La valeur implicite du trait EXTRACTION est OUI.
L'opérateur ? provoque l'affichage de la valeur du trait sélectionné. L'opérateur ?? indique que le contenu du trait sera copié dans une variable pour une utilisation future. Le paramètre variable contient le numéro de la variable.
Le fichier d'extraction accumule les résultats de la commande ANALYSEUR COMPTAGE d'une même session de travail. On peut manipuler ces listes de l'intérieur de SATO (cf. POSTE EXTRACTION). Comme SATO réinitialise le fichier «.sta» au début de chaque session de travail, on doit prendre la précaution de le renommer à la fin d'une session si on désire le conserver. Si on utilise le même nom de liste dans des commandes ANALYSEUR COMPTAGE successives, plusieurs listes portant ce nom vont se retrouver dans le fichier d'extraction.
Il est aussi possible de déposer différents résultats de comptage dans des fichiers distincts en changeant le nom du fichier d'extraction (cf. POSTE EXTRACTION CARACTÉRISER FICHIER).
Caractériser Sauvegarde
Le décompte des lexèmes par l'option FRÉQUENCES produit divers indicateurs pour chacun des lexèmes sélectionnés. On peut conserver un ou plusieurs de ces indices en caractérisant le trait SAUVEGARDE à OUI.
L'option SAUVEGARDE permet de sauvegarder les résultats du sommaire dans des propriétés lexicales entières portant le nom d'une rubrique du sommaire, à savoir : «moyenne», «écart», «répart», «discri» et «chi2». L'affectation ne s'effectuera que si la propriété existe au moment du comptage. Seules les valeurs des lexèmes décrits dans le filtre seront modifiées. Comme les valeurs sont conservées dans une propriété entière, elles sont multipliées par le multiple approprié pour faire disparaître la partie fractionnaire. Ainsi, par exemple, un chi2 de 4.17 sera transformé en 417.
L'opérateur ? provoque l'affichage de la valeur du trait sélectionné. L'opérateur ?? indique que le contenu du trait sera copié dans une variable pour une utilisation future. Le paramètre variable contient le numéro de la variable.
Caractériser Sommaire
Le sommaire fournissant divers indices statistiques sur la répartition des objets comptés peut être assez long, surtout avec l'option FRÉQUENCES. Aussi, si on sauvegarde les résultats du sommaire dans une propriété, on pourrait s'abstenir de faire afficher le sommaire. Dans ce cas, on peut caractériser le trait SOMMAIRE à la valeur NON. La valeur implicite du trait SOMMAIRE est OUI.
L'opérateur ? provoque l'affichage de la valeur du trait sélectionné. L'opérateur ?? indique que le contenu du trait sera copié dans une variable pour une utilisation future. Le paramètre variable contient le numéro de la variable.
Exemples
Exemple 1. Si l'on a segmenté le texte en documents (cf. ANALYSEUR SEGMENTATION), la commande suivante comptera le nombre de virgules par document (ici les deux documents correspondent à chacune des deux fables) en identifiant le résultat sous le titre «virgule».
On notera que nous avons inséré «\» avant la virgule dans la commande parce que «,» est un caractère spécial dans un patron de caractères.
| * ANALYSEUR COMPTAGE APPLIQUER MOTS \, DANS virgule | ||||||
| Nb-occ | Moyenne | Écart | Répart. | Discri. | Chi2 | |
| 24 | 7.36% | 2.64 | 100.0% | 0.00 | 2.91 | virgule |
Les résultats s'interprètent de la façon suivante : l'algorithme a compté 24 virgules; la fréquence relative de la virgule par document est de 7.36% avec un écart type de 2.73; la virgule est répartie dans 100% des segments dans le sens qu'elle apparaît au moins une fois dans tous les segments; par conséquent, son indice de discrimination est nul; par ailleurs, le Chi2 de 2.91 (à un degré de liberté) est significativement élevé, c'est-à-dire que la fréquence relative de la virgule dans chacune des deux fables s'écarte significativement de l'hypothèse d'une distribution uniforme.
Exemple 2. De même, la commande suivante comptera le nombre de noms propres différents (lexèmes) dans chaque chaque document».
| * ANALYSEUR COMPTAGE APPLIQUER LEXÈMES (A,B,C,D,E,F,G,H,I,J,K,L,M,N,O,P,Q,R,S,T,U,V,W,X,Y,Z)$ DANS nomprop | |||||
| Nb-occ | Moyenne | Écart | Répart. | ||
| 3 | 1.50 | 1.50 | 50.0% | nomprop | |
Les noms propres sont repérés par la présence de lexèmes débutant par une majuscule. La répartition à 50% indique qu'il n'y a présence des noms propres dans un document sur deux. La moyenne correspond ici au nombre total d'objets comptés divisé par le nombre de segments.
Indices
L'analyseur calcule d'abord des indices de répartition du décompte. Ces indices sont le nombre total d'occurrences, la moyenne par contexte des objets comptés et l'écart-type associé. On a finalement un indice de répartition, exprimé en pourcentage, qui indique la proportion de segments ou contextes où apparaît l'objet compté par rapport au nombre total de segments ou contextes. Si les objets comptés sont des occurrences de mots, la moyenne et l'écart-type seront calculés sur les fréquences relatives. La fréquence relative est le rapport entre le nombre d'occurrences de l'objet compté et le nombre total d'occurrences dans le segment ou contexte. Si les objets comptés sont des formes lexicales, la moyenne est le nombre total de formes comptées divisé par le nombre de segments ou contextes.
Pour les options FRÉQUENCES, MOTS et VALEURS, on obtient des indices complémentaires.
On a un indice discriminant dû à Salton et qui donne le poids discriminant maximum de l'objet compté pour l'ensemble des contextes considérés (cf. Salton, Gerald, Automatic Text Processing, The Transformation, Analysis, and Retrieval of Information by Computer, Addison Wesley 1989, p.279). Pour une forme lexicale donnée, cet indice est calculé de la façon suivante :
Fréq-max x ln(1/répartition)
où Fréq-max est la plus grande des fréquences relatives du lexème calculées pour chacun des contextes, et répartition est le rapport entre le nombre de contextes où apparaît le lexème et le nombre total de contextes. x indique la multiplication et ln le logarithme naturel. Cette mesure est nulle lorsque l'indice de répartition est de 100% et elle croit de façon logarithmique avec la diminution de l'indice de répartition, comme cela est illustré dans le tableau suivant :
| répartition (%) | 100 | 90 | 80 | 70 | 60 | 50 | 30 | 10 |
| ln(1/répartition) | 0.0 | 0.11 | 0.22 | 0.36 | 0.51 | 0.69 | 1.20 | 2.30 |
Finalement, on a un Chi2 qui mesure l'écart entre les fréquences relatives observées et les fréquences relatives attendues sous l'hypothèse d'une répartition uniforme de l'objet compté. Le nombre de degrés de liberté du Chi2 est de n-1 où n est le nombre de contextes. Lorsque le nombre de degrés de liberté dépasse 30, on utilise plutôt la loi normale pour vérifier si l'écart type observé s'écarte significativement de la moyenne attendu. La mesure d'écart sera ramenée à l'échelle de la courbe normale centrée réduite, c'est-à-dire de moyenne 0 et de variance 1. C'est l'écart réduit, aussi appelé cote Z = (X - µ)/σ, où µ est la moyenne arithmétique et σ est l'écart type. X est la répartition observée et Z est sa transformation à comparer à la courbe normale centrée et réduite.
L'indice de Salton et la mesure du Chi2 (ou cote Z) n'ont pas la même portée. Le Chi2 s'applique aux objets fréquents ayant un fort taux de répartition. Inversement, l'indice de Salton, de nature heuristique, est destiné aux objets peu fréquents et ayant un faible taux de répartition.
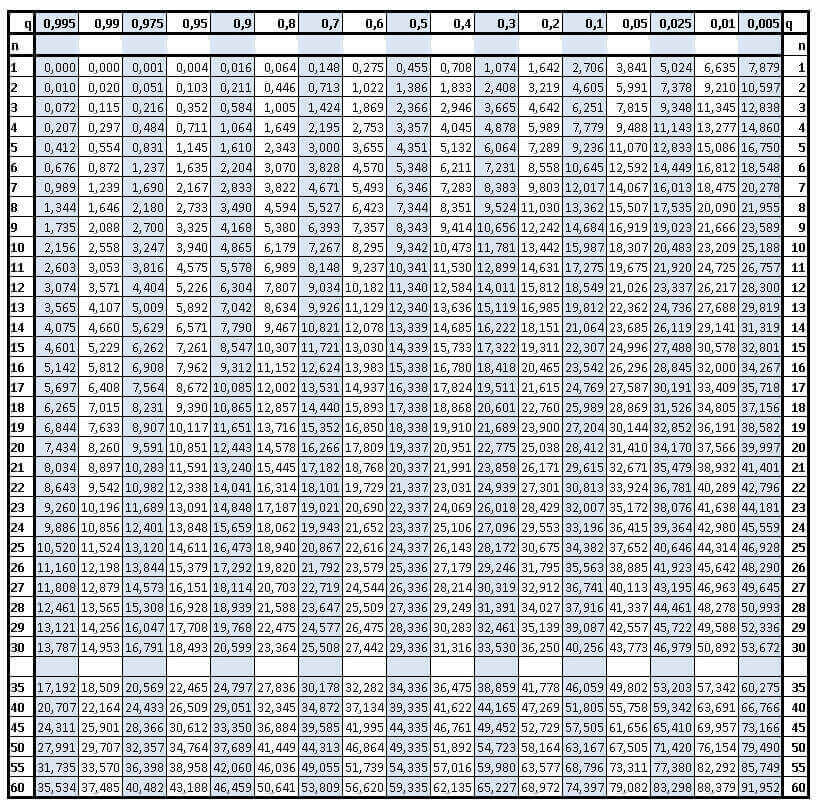
Table du Chi-carré (Khi²)
La table donne les valeurs de Khi² en fonction de celle du risque d'erreur q et du nombre n de degrés de liberté. Si la valeur calculée du Khi² dépasse la valeur de la table, on en tirera la conclusion que la distribution sur les segments de l'élément examiné n'est pas uniforme avec un risque d'erreur de q%.
(Source du tableau)